













Five operators for Apache Cassandra have been created that have made it easier to run containerized Cassandra on Kubernetes. Recently the major contributors to these operators came together to discuss the creation of a community-based operator with the intent of making one that makes it easy to run C* on K8s. One of the project’s organizational goals is that the end result will eventually become part of the Apache Software Foundation or the Apache Cassandra project.
The community created a special interest group (SIG) to set goals for what the operator should do at different levels to find a path for creating a standard community-based operator. The Operator Framework suggests five maturity levels for operator capabilities starting from basic installation to auto-pilot.
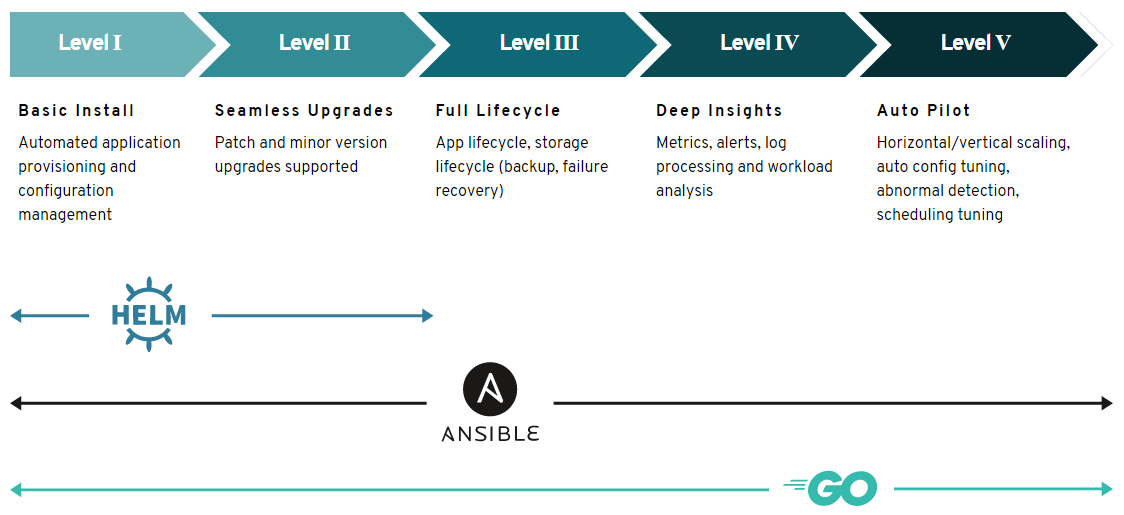
(Source: OperatorFramework.io)
The five Cassandra Kubernetes operators all come from different backgrounds, so the first major goal is to develop a common understanding as to what an operator needs to do and at which level. This first step involves collaborating on a Custom Resource Definition (CRD) that will set the syntax / schema which will be used to create Cassandra clusters on Kubernetes. Once this is done, a software extension can be developed in a variety of languages including Go, Java, or using the Operator SDK in Helm or Ansible without making changes to Kubernetes.
We’re not starting from zero, as the creators of the five operators are actively participating in the SIG. Hopefully much of the decided upon CRD will have code fragments that can be leveraged from the other projects. The major operators out publicly today are those by Sky UK, Orange Telecom, Instaclustr, Elassandra, and DataStax (list sourced from the awesome-cassandra project):
-
CassKop - Cassandra Kubernetes Operator - This Kubernetes operator by Orange automates Cassandra operations such as deploying a new rack aware cluster, adding/removing nodes, configuring the C and JVM parameters, upgrading JVM and C versions. Written in Go. This one was also one of the first ones out and is the only one that can support multiple Kubernetes clusters using Multi-CassKop
-
Cassandra Operator - A Kubernetes operator by SkyUK that manages Cassandra clusters inside Kubernetes. Well designed and organized. This was among the first operators to be released.
-
Instaclustr - Kubernetes Operator for Cassandra operator - The Cassandra operator by Instaclustr manages Cassandra clusters deployed to Kubernetes and automates tasks related to operating an Cassandra cluster.
-
Cass Operator - DataStax’s Kubernetes Operator supports Apache Cassandra as well as DSE containers on Kubernetes. Cassandra configuration is managed directly in the CRD, and Cassandra nodes are managed via a RESTful management API.
-
Elassandra Operator - The Elassandra Kubernetes Operator automates the deployment and management of Elassandra clusters deployed in multiple Kubernetes clusters.
If you’re interested in catching up on what the SIG has been talking about, you can watch the YouTube videos of the sessions and read up on the working documents:
As with any Kubernetes operator, the goal is to create a robot which takes the manual work of setting up complex configurations of containers in Kubernetes easier. An operator can also be seen as a translator between the logical concepts of the software and the concrete Kubernetes resources such as nodes, pods, services. Combined with controllers, operators can abstract out operations such that the human operators can focus on problems related to their industry or domain. As mentioned above, the different operator capability levels offer a roadmap to creating a robust operator for Cassandra users that is easy to use, set up, maintain and upgrade, and expand a cluster.
When a platform needs Cassandra, it’s probably exhausted the other potential datastores available because it needs high availability and fault tolerance, at high speeds, around the world. Kubernetes is a technology that can match well with Cassandra’s capabilities because it shares the features of being linearly scalable, vendor neutral, and cloud agnostic. There is a healthy debate about whether Cassandra belongs in Kubernetes — and whether databases belong in Kubernetes at all — because other orchestration tools are good enough, though the growing user base of Kubernetes in hobby and commercial realms suggests that we need to provide an operator that can keep up with the demand.
Most likely if someone is thinking about moving Cassandra workloads from public cloud, on-premises VMs, or even on-premises bare metal servers to either a public or private cloud hosted K8s, they’ll want to evaluate whether or not the existing architecture could run and be performant.
As part of the SIG, we’re also coming up with reference architectures on which to test the operator. Here are some of the common and most basic reference architectures that are likely candidates.
-
Single Workload in Single Region
-
1 DCs in 1 region, with 3 nodes (3 total)
-
DC expands to 6 (6 total)
-
DC contracts to 3 ( 3 total)
-
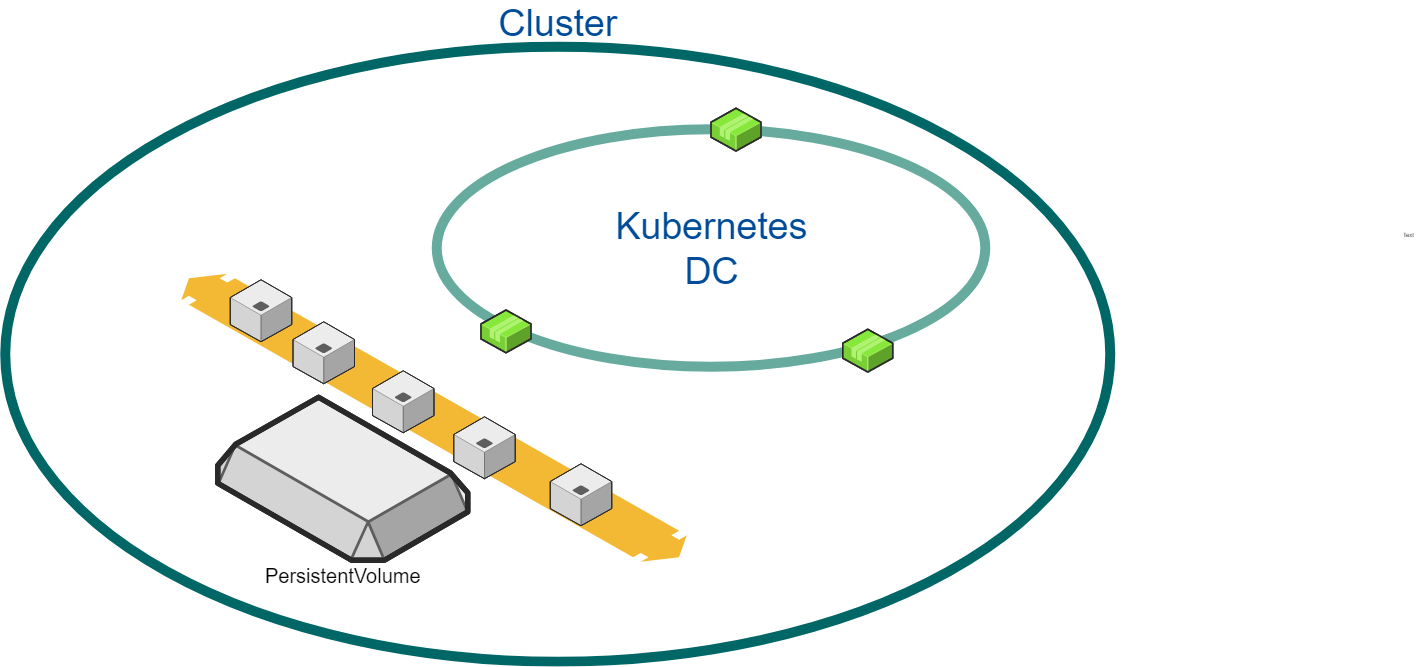
-
Multi-Workload in Single Region
-
2 DCs, both in the same region, with 3 nodes in each DC (6 total)
-
Both DCs expand to 6 each (12 total)
-
Both DCs contract to 3 each ( 6 total)
-
Add a third DC in the same region with 3 nodes (9 nodes)
-
Remove third DC
-
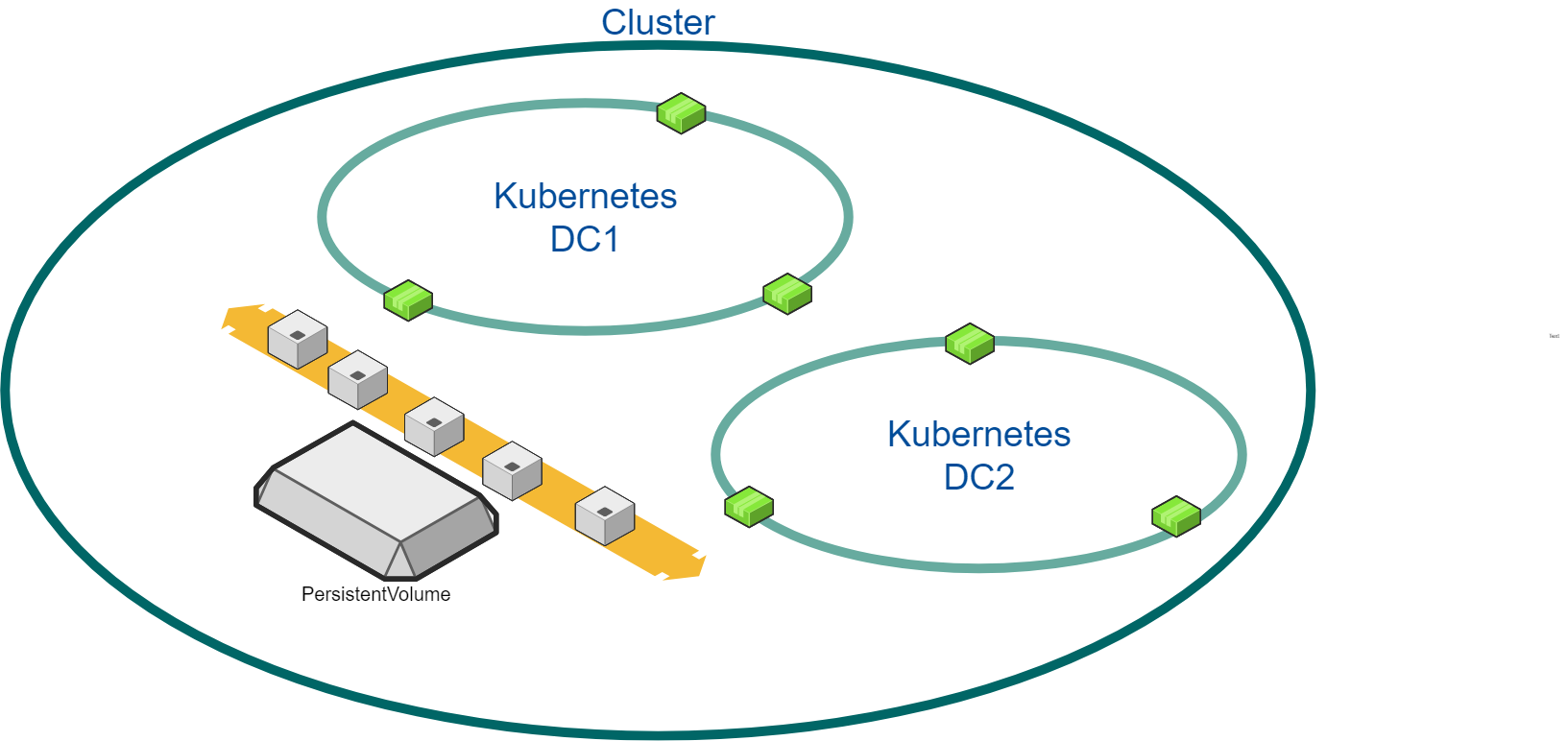
-
Single Workload in Multi-Regions
-
2 DCs, 1 in each region, with 3 nodes in each DC (6 total)
-
Both DCs expand to 6 each (12 total)
-
Both DCs contract to 3 each ( 6 total)
-
Add a third DC in a 3rd region with 3 nodes (9 total)
-
Remove third DC Although each organization is different, these scenarios or combinations of these scenarios account for 80% of most pure Apache Cassandra use cases. The SIG would love to know more about Cassandra users’ use cases for Kubernetes. Please take this short survey, which will remain open through September 17, 2020.
-
Join the biweekly meetings to stay informed.